


图书目录中依然延续至今的信息片段:书名、作者或整理、主题、简介和篇幅。但如今其含有更多的信息,如
出版社、出版时间、定价、条形码和上架建议等等。

图书馆无法管理的自己图书,很难统计馆内多少图书、每类图书多少
图书馆无法根据大众读者喜好摆放某类图书的位置
读者无法找到自己想读的图书
读者费时费力地找到了图书,但内容与描述不符
读者精疲力尽地找到了图书,但无法快速定位到某些章节
读者心平气和地找到了图书,但内容是错误的
读者心满意足地找到了图书,但内容是下册的,又必须从上册读起
读者喜出望外地找到了图书,但内容是用甲骨文写的,用梵文作的注解(读者看不懂)
读者欲哭无泪地找到了图书,但图书馆要下班关门了
......读者崩溃了.....
“元数据是关于数据的数据”(准确地说这个定义不大实用,且不易被理解)。从数据、信息、知识和智慧人类
认知领域的层次结构来讲,数据是通过工具或机器搜集的原始资料。确切地说,数据是原始、未经处理的资
料或潜在信息。信息就是经过某种处理并供人使用的数据。知识指的是你知道的事情,也就是经过内化的信
息,而智慧则是指了解如何运用知识。元数据是对潜在信息的信息,是关于数据的更高层次抽象,是对数据
的描述。
准确的元数据是必不可少的,也是迅速有效地对数据去粗取精的关键。没有元数据,数据就毫无意义,只不过
是一堆数字或文字而已。
元数据只是发挥数据价值的充分条件,“酒香也怕巷子深”如制定了合理并严格执行数据标准,通用的易用的模
型设计数仓底座,极高的良性循环的数据质量,安全的顺滑的数据访问和数据共享机制和合理的高效的管理流
程等,就亟须统一标准的、合理的、易用理解的、易用使用的元数据管理系统,不能把“好酒”(数据)埋没
掉,要把数据宣传出去,让更多用户知晓、理解和高效使用,并使数据价值得最大发挥。
同时也应避免言过其实的“金玉其外,败絮其中”即数据不标准、数据质量较差、数据存在异常和形散而神散、
重复建设及计算的数仓等等,即使有个华丽的元数据可视化展示,只会换来业务用户更多抱怨。
总之,名副其实是最好的,数据与元数据同步持续良性迭代优化。
元数据应用领域较广,种类甚多,按照不同应用领域或功能,元数据分类有很多种方法或种类,元数据一般大
致可为三类:业务元数据、技术元数据和操作元数据。各自包含内容如下:
业务元数据:
指标名称、计算口径、业务术语解释、衍生指标等
数据概念模型和逻辑模型
业务规则引擎的规则、数据质量检测规则、数据挖掘算法等
数据血缘和影响分析
数据的安全或敏感级别等
技术元数据:
物理数据库表名称、列名称、列属性、备注、约束信息等
数据存储类型、位置、数据存储文件格式或数据压缩类型等
数据访问权限、组和角色
字段级血缘关系、ETL抽取加载转换信息
调度依赖关系、进度和数据更新频率
操作元数据:
系统执行日志
访问模式、访问频率和执行时间
程序名称和描述
版本维护等
备份、归档时间、归档存储信息
元数据也是数据,同样适用数据生命周期管理。元数据生命周期可分为采集、整合、存储、分析、应用、价值
和服务几个阶段。
元数据架构
元数据战略是关于企业元数据管理目标的说明,也是开发团队的参考框架。元数据战略决定了企业元数据架
构。元数据架构可分为三类:集中式元数据架构、分布式元数据架构和混合元数据架构。
集中式元数据架构:
集中式架构包括一个集中的元数据存储,在这里保存了来自各个元数据来源的元数据最新副本。保证了其独立
于源系统的元数据高可用性;加强了元数据存储的统一性和一致性;通过结构化、标准化元数据及其附件的元
数据信息,提升了元数据数据质量。集中式元数据架构有利于元数据标准化统一管理与应用。
分布式元数据架构:
分布式架构包括一个完整的分布式系统架构只维护一个单一访问点,元数据获取引擎响应用户的需求,从元数
据来源系统实时获取元数据,而不存在统一集中元数据存储。虽然此架构保证了元数据始终是最新且有效的
,但是源系统的元数据没有经过标准化或附加元数据的整合,且查询能力直接受限于相关元数据来源系统的可用性。
混合式元数据架构:
这是一种折中的架构方案,元数据依然从元数据来源系统进入存储库。但是存储库的设计
只考虑用户增加的元数据、高度标准化的元数据以及手工获取的元数据。
这三类各有千秋,但为了更好发挥数据价值,就需要对元数据标准化、集中整合化、统
一化管理。如果企业做功能较为完善的数据资产管理平台可采用集中式元数据架构。
元数据生命周期
笔者这里以集中式元数据架构为例讲解,通过对数据源系统的元数据信息采集,发送Kafka消息系统进行解
耦合,再使用Antlr4开发各版SQL解析器,对元数据信息新增、修改和删除操作进行标准化集中整合存储。
在元数据集中存储的基础上或过程中,可提供元数据服务与应用,如数据资产目录、数据地图、集成IDE
、统一SQL多处理引擎、字段级血缘关系、影响度分析、下线分析、版本管理和数据价值分析等(这些元
数据应用可根据产品经理设计理念进行优化组合,笔者这里拉平排列各功能应用,为了方便讲解各元数据应
用模块)。这里就包括了元数据采集、整合、存储、分析、应用等阶段的生命周期。
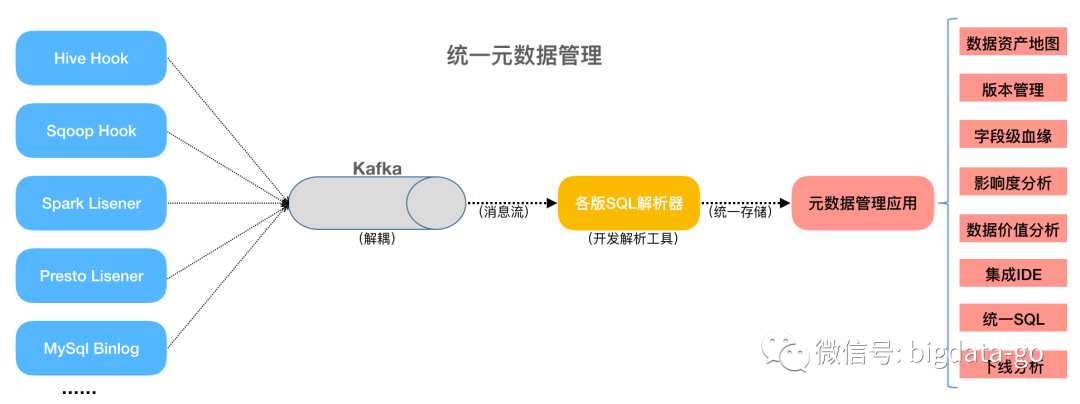
元数据管理与常见元数据应用:
数据资产地图
数据资产地图包括数据资产目录和血缘关系等。通过对元数据的标准化、加工整合形成数据资产地图。数据资
产地图一般可支持全文搜索和模糊查询表信息检索、也支持按照关系查找或按主题域层级查找。一般采集
Elasticsearch做元数据信息检索和Neo4J做血缘关系的数据地图。如图:

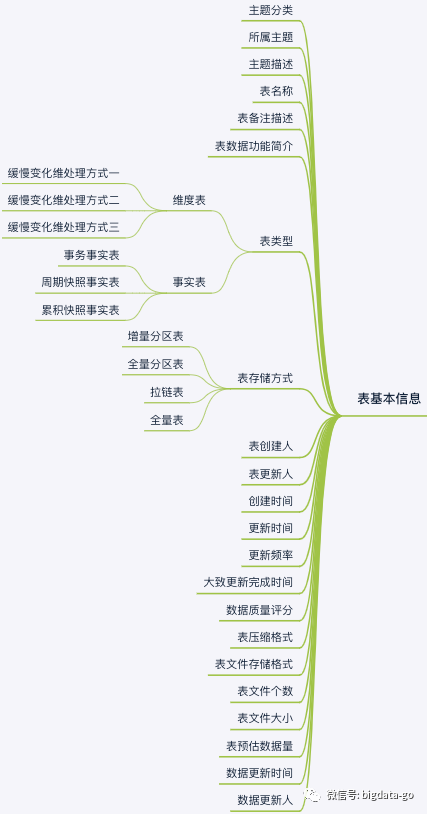
检索表的元数据信息包括分层信息、分层数据库数量、每层功能描述、数据库表数量、总计存储大小、存储类
型、实际表存储位置,表基本信息包括主题分类、所属主题、主题描述、表名称、表数据功能简介、表类型、
表创建人、表更新人、创建时间、更新时间、数据更新人、数据更新时间、表预估数据量、表文件大小、表文
件个数、表文件存储格式、表压缩格式、数据质量评分、数据热度、更新频率、大致更新完成时间等等。
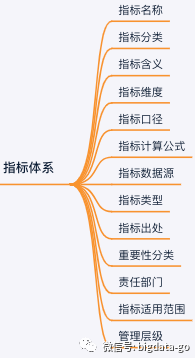
还包含指标业务元数据信息如下:
元数据信息也要包括归档和已销毁的数据记录的元数据信息。归档元数据信息便于数据分析师查找,快速恢
复,重新使用挖掘出数据价值。已销毁元数据信息便于数据安全管理。
还包括未采集数据资产管理平台的元数据信息,实际数据还分布在各个源系统的数据,需要抽取、转换、清洗
和加载到数据平台的相关流程和ETL工具,便于业务用户元数据查找和数据使用。
版本管理
元数据版本管理功能,可对元数据进行发布、查看历史版本、导出历史版本和版本对比操作。在元数据未发布
或未正式上线使用时,其他仅有使用权限的用户无法查看此版本信息,这样保证了元数据系统权威性和可靠
性。这里同样涉及影响度分析和下线分析元数据应用模块,如表结构变更、删除等下游系统都能做到动态感知
提醒或告警功能,下线分析也是如此。
血缘关系
血缘关系包含了集群血缘关系、系统血缘关系、表级血缘关系和字段血缘关系,其指向数据的上游来源,向上
游追根溯源。这里指的血缘关系一般是指表级和字段级,其能清晰展现数据加工处理逻辑脉络,快速定位数据
异常字段影响范围,准确圈定最小范围数据回溯,降低了理解数据和解决数据问题的成本。
在传统的ETL工具如Informatica、DataStage和开源Kettle中都有相应血缘关系,以informatica ETL工具的表级
血缘关系和字段级血缘举例,如图:
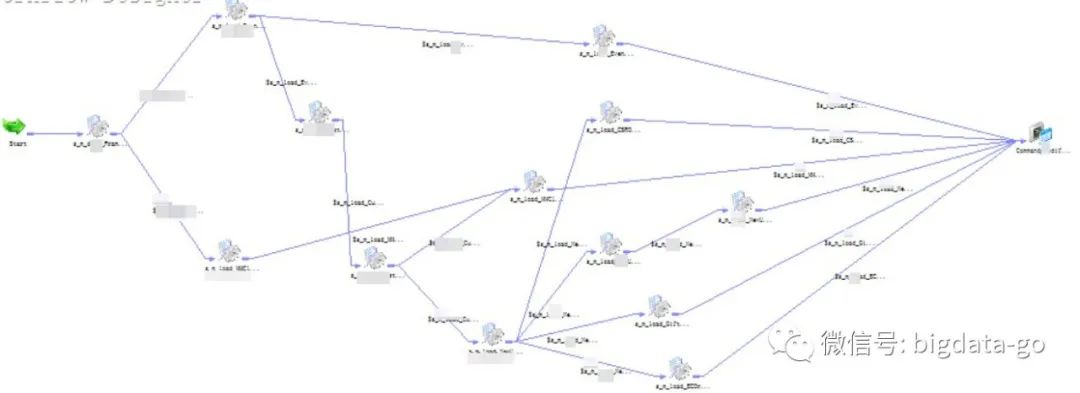
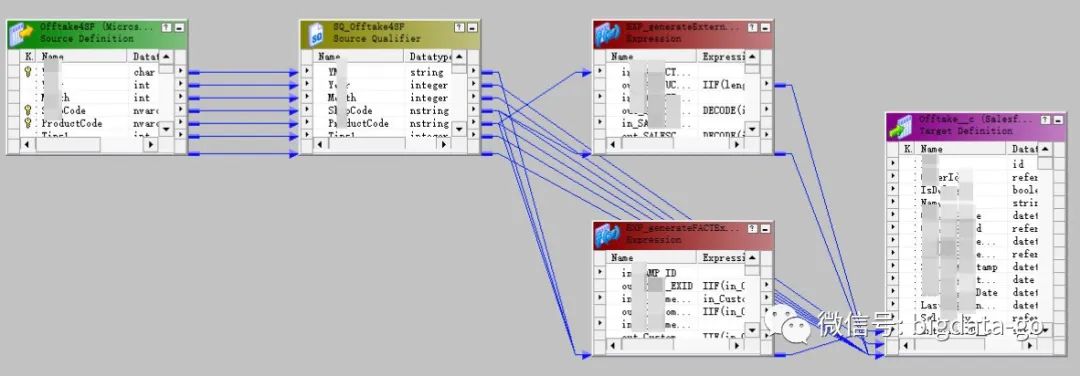
但只能展现使用这些传统ETL工具的血缘关系,其他方式ETL却无法生成血缘关系。其不灵活也不便于元数据统一集中管理。
大数据时代,大部分企业数据仓库都使用Hive作为数仓存储和ETL数据加工,如果是单一Hive处理引擎,可使
用Hive Hook直接解析字段级血缘关系和表级别血缘关系。如果多种计算引擎就使用上述笔者给出技术架构
图,通过对不同存储和计算引擎监听动作,使用Antlr4开发各版本SQL解析工具,动态识别元数据信息变更、
删除和新增实时或准实时生成集群血缘关系、系统血缘关系、表级血缘关系和字段血缘关系。通过从语法树遍
历解析后存储Neo4j图数据

影响度分析
下线分析
数据价值分析
集成IDE
统一SQL路由引擎